Append is Near: Log-based Data Management on ZNS SSDs

The third paper from CIDR 2022 that I’m covering is the paper that talks about ideas to improve log-based data management on Zoned Namespace (ZNS) SSDs.
Zoned Namespaces in SSD
Zoned namespaces are a new NVM SSD interface that was introduced around 2020, instead of every application writing blocks interleaved in SSDs, ZNS can divide an SSD into fixed-sized zones, and allow the application to decide which SSD zone to write data from.

Having fixed zones in SSDs, allows each zone to be garbage collected together and helps reduce a lot of the write amplification issues with SSDs.
This also creates more opportunities for data applications to utilize the new commands that are introduced with ZNS, such as Zone Append which directly appends data into each zone without keeping track of which block / tail the zone has written to. Using Zone Append, data applications no longer have to keep track of pointers and perform locking, which also improves performance as SSD can write data on better hardware alignment as well.
(For more details can also refer to this material from Vault 2020)
Group Append
The paper proposed a new command to be introduced into ZNS, which is an even simpler version of Zone Append. Zone Append requires each writer to write out a block size of data, which essentially means the application has to keep a buffer internally and do the bookkeeping necessary to flush. Group Append allows the SSD controller to take any arbitrary size of writes and can buffer data on the device level.
How software / hardware codesign improves data management
The paper went on to discuss how various data management systems (log-based file systems, RocksDB, Databases, and Event logs) can leverage ZNS SSD and new commands like Group Append can change how the software is designed, also further possible research directions for each as well.
I won’t cover every improvement proposal, so I'm just picking a few to highlight.
RocksDB is a key-value store that uses an LSM (Log-structured merge) tree to store data, which internally keeps an append-only key-value pair structure called SSTables (Sorted String Tables).
With normal SSDs, RocksDB will be writing out SSTables to disk which blocks will be interleaved with other IO writes. Since the design of LSM is to store multiple levels of SSTable cache, each time an SSTable with a particular level is merged to write out to the upper level, data needs to be both removed and written to the new level. This causes write-amplification on the SSD that reduces the lifetime of the disk, and also performance wise isn’t the most optimal.
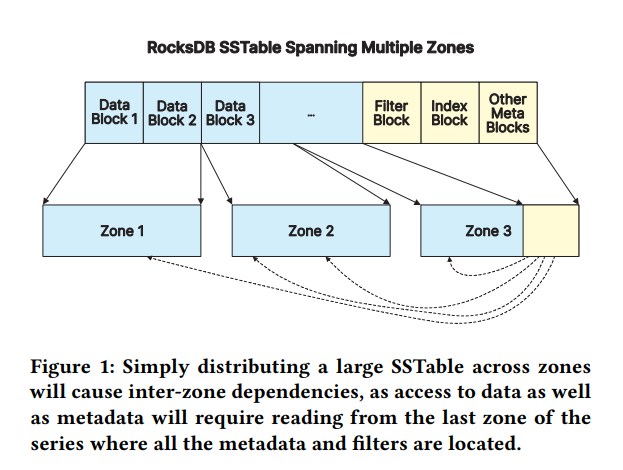
Using ZNS SSD, we can now map the SSTable data blocks that have the same lifetime into each zone. This allows the LSM tree to instruct the SSD to remove the entire zone in one command, which greatly reduces write amplification and improves efficiency.
However, this also brings more research directions and questions with this approach, listing a few here:
What is the most optimal way to distribute the data blocks with zones given the data blocks will vary in size?
How do we store the metadata associated with the SSTables, as it could involve a lot of random writes?
Relational Databases such as MySQL currently write all the transactions into a write-ahead log (WAL) which allows the databases to recover their state in restarts. With normal SSDs, it’s up to the DBMS to understand how and when to flush the WAL files among multiple log writer threads into different files concurrently.
With ZNS SSD and Group Append, we can move each file write to each zone, and each writer can send Group Append with data to the SSD device controller without buffering on the DBMS side. This allows a lot more frequent commits and more efficient implementations, trading off more activities and buffering on the controller side. This also allows the DBMS to efficiently remove WAL by erasing zones directly.
Similarly, this brings more research directions. One example is how can we redesign the DBMS implementation even further, assuming all the incoming changes can be stored effectively to WAL with Group Append, DBMS should be able to just track these appends commit IDs with additional metadata and simplify what it needs to record in its own database persistent logs.
Last words
It’s exciting to see the continuous improvements that happen on the hardware side, and how software can be redesigned that brings a lot more efficiency.
Seeing changes like this also is a reminder that improvements to the disk storage are not just about the cost and performance of IO, but also additional software commands that controllers can bring that can perform operations a lot more efficiently.