Pylive: On-the-Fly Code Change for Python-based Online Services

Pylive: On-the-Fly Code Change for Python-based Online Services (ATC 2021), From Haochen Huang, Chengcheng Xiang, Li Zhong, and Yuanyuan Zhou, University of California, San Diego
Running a high availability online service is still challenging today, as there are many factors that can cause a service to fail, especially when trying to keep your code shipping velocity at a decent pace (aka “Move fast and break things”). And it’s extremely painful to debug and find root causes in online services.
Most infra teams today rely on monitoring metrics and logs, and when there isn’t enough information then making code changes to add logs or instrumentation and redeploy the online services to get more clues.
The problem with this approach is that redeploying and restarting services is usually not a straightforward process, depending on how much infrastructure is set up to do blue/green deployments, traffic steering, etc. Therefore, it’s usually very hard to make changes to acquire more data to debug in a production environment.
Another problem is when a service is restarted, all the in-memory state is lost which makes warming up the service and debugging extra hard especially when the issue only occurs in particular load conditions.
Pylive is looking to change this by allowing engineers to make code changes on the fly without the need to restart a service, and we will go over some of the important elements of how this is done.
What is Pylive?
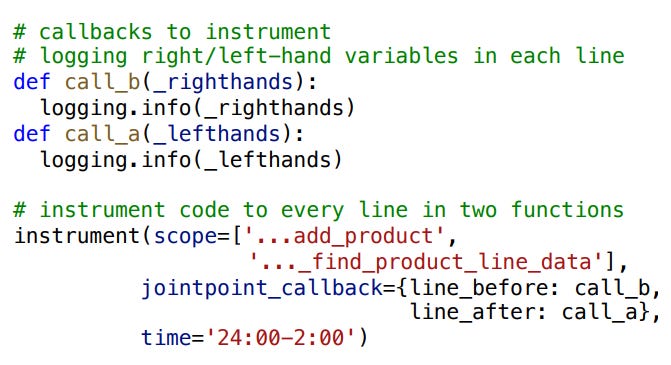
Pylive is a library that developers can import into their code and runs a separate server that allows requests to be made to the current running python program.
Developers can then add more instrumentation or profiling to existing code by adding callbacks wrapped around functions or patching whole python functions without restarting the service.
Challenges of updating code live
There are several challenges when it comes to implementing Pylive:
How do we modify the running code?
When can we modify the code?
How do we handle multi-threaded / processes updates?
To address the first problem, Pylive leverages the dynamic typing and object model in Python, since each variable type in Python can be changed dynamically, changing an existing argument or variable’s type is just a local change and doesn’t require program-wide modification. Comparing this to statically typed languages like Java or C++, modifying an existing function type often means modifying the underlying VM or binary which is very tricky. Therefore, leveraging the ability to replace code (obj.__code__) and functions dynamically without any underlying changes is a very convenient way of fully leveraging the power of dynamic languages like Python.
The more tricky problem is when it is safe to modify code, as changing code in the middle of execution can be really tricky. Using the following as an example, modifying code in a critical section in between locks can lead to undefined outcomes.

There is no guaranteed automated way to detect what section is safe to modify, so this relies on developers specifically stating which section is safe to change and when which is also referred to as a safe point.
One safepoint that Pylive supports is to replace a function when there is no active caller, which Pylive supports by scanning all thread stacks for any active reference of that section.
Another safepoint is to call a user-provided function to check if it’s safe to modify the code, which in the previous example allows the developer to write code to check if the previous lock is still being held.
The last problem to handle is multi-threaded and processes update. Multi-threading is easier to support in Python given there is a single global lock (GIL), therefore if the Pylive thread is able to hold on to the GIL then it is safe to evaluate safepoints and modify. In a multi-process situation, each subprocess is spawned with a Pylive listener that is able to receive requests, and a single controller dispatches code change requests to all subprocesses.
Why this is useful & Implications
The most obvious value this brings is the ability to add logging and instrumentation, or even add patches to live running production code without waiting for this loop:
code → build → verify → deploy → wait until conditions hit
Although in practice, in larger organizations allowing developers to change production on the fly without any verification is a dangerous step as it can make existing problems even worse.
However, I do think that there is a new paradigm of development that is changing how developers develop, build, test and deploy and debug code.
The current state of the art of ensuring production systems’ quality is still mostly about storing and reacting to information from monitoring systems. This includes watching what metrics and logs have been produced (e.g: Datadog), piecing together how services/requests work (e.g: Lightstep), managing and triaging incidents together (e.g: Jelli), etc.
One new wave of startups is moving towards ensuring software quality by shifting left quality checking, either by faster integration tests (e.g: Signadot), replaying API traffic (e.g: Speedscale), or automated quality, and security scanning (e.g: Levo.ai, Optic).
Now there are also a new set of companies tackling the idea of capturing more detailed information at a code level (e.g: Polar Signals) and also replay code executions (e.g: Replay.io) also debug in production (e.g: Rookout, Thundra).
Pylive or similar research is helping to move to build this new development and debug experiences in a more feasible way, as tools get deeper into a language level, it provides a richer set of interactions that developers can be able to interact with services.
Getting into the language object model not just allows you to change code on the fly, but also captures a lot richer information that helps potentially replay production incidents on your laptops, or capture live state capturing in prod from your IDE, to collaboratively modify code in production with a sign off process, etc.
With more powerful tools certainly comes with greater responsibility, but I believe the flexibility and agility that teams can unlock will continue to push the tools towards this direction overall.