Self-organizing Data Containers
CIDR 2022 #5

Hi all! We’re onto the 5th paper in the CIDR 2022 series, which is from the MIT CSAIL group, proposing a new data storage format for data systems to be stored in the cloud.
This is a paper that I have a strong interest in as I’ve seen how the industry evolved in creating file formats (Avro, Parquet, Arrow) and also invested in companies like Tabular and Eto Labs that are also building new systems that include new data formats like Apache Iceberg and Rikai.
Disaggregated Data Services
Like the Data Lakehouse paper, I covered previously, we’re seeing systems are going on step beyond the separation of storage and compute, but also having storage layer leveraging Cloud storage like S3 that’s shared among multiple compute frameworks.
One of the challenges with this architecture was maintaining data consistency, which is what Apache Iceberg and Databricks’s Delta lake aim to solve.
However, one particular challenge that isn’t solved is performance. The example used in the paper was Redshift vs Redshift Spectrum (loads external data on query time), which performs 8x slower due to the slower I/O to S3 and inefficiency of not being able to load and structure the data in an optimal way as the data is serialized into a standard format (e.g: Parquet, Arrow) without any additional data structures (index, etc) that is typically maintained in memory in the database engine itself.
Self-Organizing Data Containers
The core idea of the paper is to augment the data format that’s being stored in the cloud, into what the author calls self-organizing data containers (SDC). Modern high performance data systems usually able to achieve high performance by storing and building additional metadata such as indexes, determine and change efficient compression based on data, also applying physical data layout changes such as clustering and partitioning based on data stored and also materialized views against the data.
Instead of having a single data systems such as Redshift or Snowflake create and maintain these data in a silo, data containers is meant to bundle these data in the data format so all systems accessing the same data can leverage these performance metadata and optimizations.
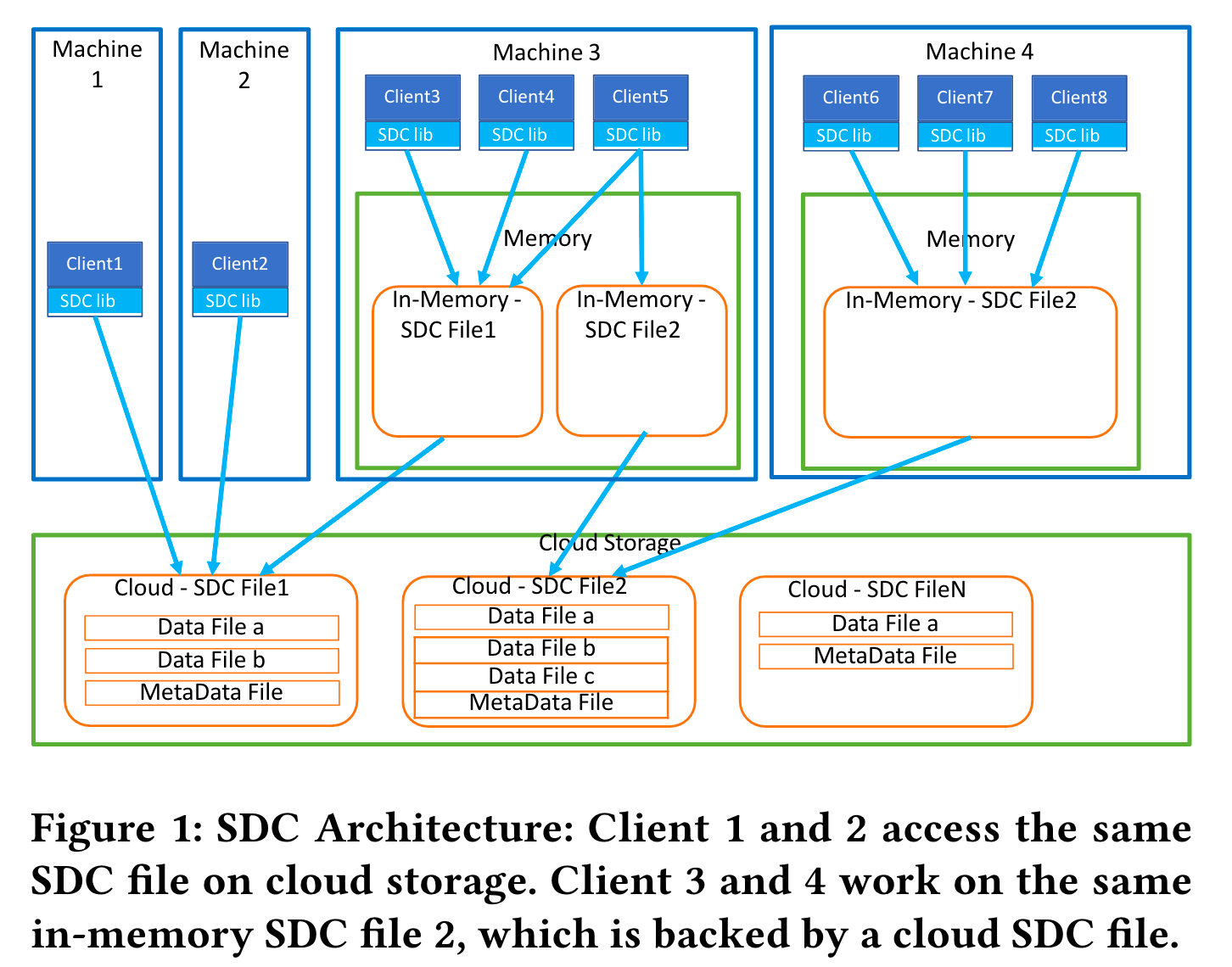
SDC includes client libraries that directly access storage or in-memory to read SDC files without any intermediate services. The client libraries is able to publish metadata about the SDC and also make optimizations to the SDC based on its read patterns. These optimizations can include creating materialized views, replicating part of the SDC for frequently accessed data, creating and updating indexes or storage layout, etc.
The challenge is to be able allow clients concurrently access and modify SDC without performing conflicting operations.

A SDC besides storing data blocks like Arrow or Parquet in columnar fashion, also includes index blocks and metadata blocks. All SDC must include one Index block that contains a sparse row index that maps row id ranges to blocks.
However, additional index blocks can be created for more efficient access. The paper uses the example of creating a quad-tree index that allows efficient lookup for finding range of two attributes. Clients can further create more splits of a quad-tree quadrant when it finds frequent access in a region, by creating more data blocks and creating a new index block. By evolving the indexes and the data blocks, the SDC becomes self-evolving over time through the clients.
SDC vs Delta Lake

Comparing SDC and Delta Lake both stored on disk, SDC can perform up to 10x speedup through optimal range partitioning using the mentioned quad-tree index, while Delta Lake only optimizes 1.25x using z-ordering. The biggest reason Delta Lake isn’t able to perform efficiently in this use case is that the z-order isn’t optimized to the workload access that is observed, while SDC can based on the access pattern evolve to have more efficient indexes.
Last Thoughts
The paper has left a lot more research directions and questions to be answered, such as how to coordinate optimizations being done among different clients to perform optimal outcomes with the same goal, or how to create incremental changes to the data layout and what policy to apply this for.
Nonetheless, I do find this research direction really interesting as I think we are going to see more efficient data access and performance optimizations into the data format layers that is designed for particular workload patterns.
This creates a new interesting paradigm where we see the decoupled database systems continue to evolve where query, compute, storage are being unbundled and shared among systems. We’re already seeing projects and companies moving towards this direction and excited to see how this unfolds.